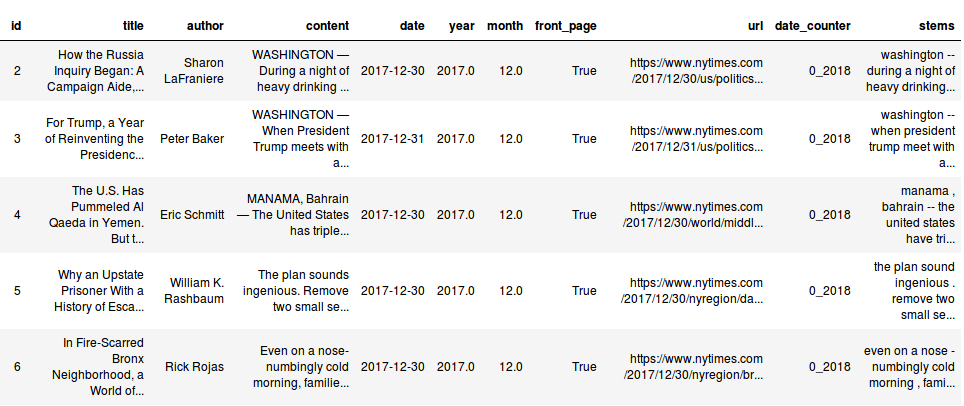
10,700 articles from the front page of the Times
Articles from the front pages of the print and web versions of The New York Times, the very end of 2017 to mid-late 2018. Articles were taken using archive.org’s Wayback Machine, visiting the the capture of nytimes.com for every day from January 1, 2018 to December 31, 2018 and sampling articles from “Today’s Paper” on page A1 and sampling an equal number of articles from the website, from top to bottom.
Includes title, author, article content, date, year, month, a boolean value for whether the article was in the print version (front_page == True) or the web version (front_page == False), the position in the archive.org calendar from which the article was taken (e.g., date_counter == “0_2018” if the article was taken on the first day of 2018’s archive.org calendar for nytimes.org), and the stemmed article content, processed using spaCy.
Note: The way in which archive.org captures websites sometimes means that the capture of nytimes.com for a given day could contain a “Today’s Paper” link for a previous day. Accordingly, in the print version particularly, duplicate articles can appear on two days. This dataset should therefore be considered a bootstrapped sample.