All the News 2.0 — 2.7 million news articles and essays from 27 American publications
THIS DATASET IS FOR NON-COMMERCIAL, RESEARCH PURPOSES ONLY. IT IS VERY MUCH NOT FOR TRAINING COMMERCIAL GENERATIVE MODELS.
Overview
This dataset contains 2,688,878 news articles and essays from 27 American publications, spanning January 1, 2016 to April 2, 2020. It is an expanded edition of the original All the News dataset on Kaggle, which was compiled in early 2017. While the original dataset contains more than 100,000 articles, the new dataset's greater size and breadth should allow researchers to study a wider selection of media.
Changelog
7/9/22
- Removed a Washington Post article with null values
- Applied int type to days and years that were str.
- Removed Unnamed columns.
Description
Each row contains the following data:
date(str): Datetime of article publication.year(int): Year of article publication.month(float): Month of article publication.day(int): Day of article publication.author(str): Article author, if available. Multiple authors are separated by a comma.title(str): Article title.article(str): Article text, without paragraph breaks.url(str): Article URL.section(str): Section of the publication in which the article appeared, if applicable.publication(str): Name of the article publication.
The yearly breakdown of articles is as follows:
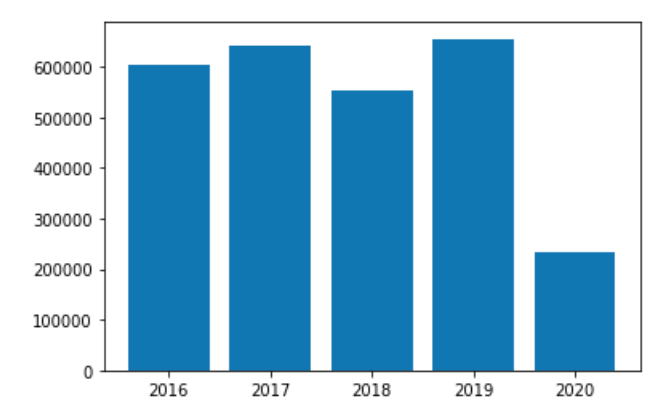
| Year | Count |
|---|---|
| 2016 | 604511 |
| 2017 | 640493 |
| 2018 | 553588 |
| 2019 | 655456 |
| 2020 | 234830 |
Representation of publications in the data is as follows:
| Publication | Count |
|---|---|
| Axios | 47815 |
| Business Insider | 57953 |
| Buzzfeed News | 32819 |
| CNBC | 238096 |
| CNN | 127602 |
| Economist | 26227 |
| Fox News | 20144 |
| Gizmodo | 27228 |
| Hyperallergic | 13551 |
| Mashable | 94107 |
| New Republic | 11809 |
| New Yorker | 4701 |
| People | 136488 |
| Politico | 46377 |
| Refinery 29 | 111433 |
| Reuters | 840094 |
| TMZ | 49595 |
| TechCrunch | 52095 |
| The Hill | 208411 |
| The New York Times | 252259 |
| The Verge | 52424 |
| Vice | 101137 |
| Vice News | 15539 |
| Vox | 47272 |
| Washington Post | 40882 |
| Wired | 20243 |
Method
Publications were scraped with Python according to the publications' sitemaps, with a few exceptions (like Vox) involving RSS feeds. The last day of scraping was on April 2, 2020.